Performance¶
Yara ORM is built to be a fast async Python ORM: the per-query hot path (parameter binding, row decoding, pooling) runs in compiled Rust, so steady-state overhead is far lower than pure-Python ORMs. The numbers below compare Yara ORM against eight other Python ORMs — Tortoise ORM, async SQLAlchemy 2.0, Pony ORM, Django ORM, Peewee, SQLObject, Ormar and Piccolo — on identical workloads.
Methodology
Each ORM gets its own table and the same workload and data. Every operation is timed
BENCH_REPEAT times and the median is reported, so warm steady-state (driver and
prepared-statement caches hot) dominates over cold-start noise. Treat the numbers as
indicative throughput, not a micro-benchmark. Full methodology and the runnable script
live in benchmarks/.
PostgreSQL¶
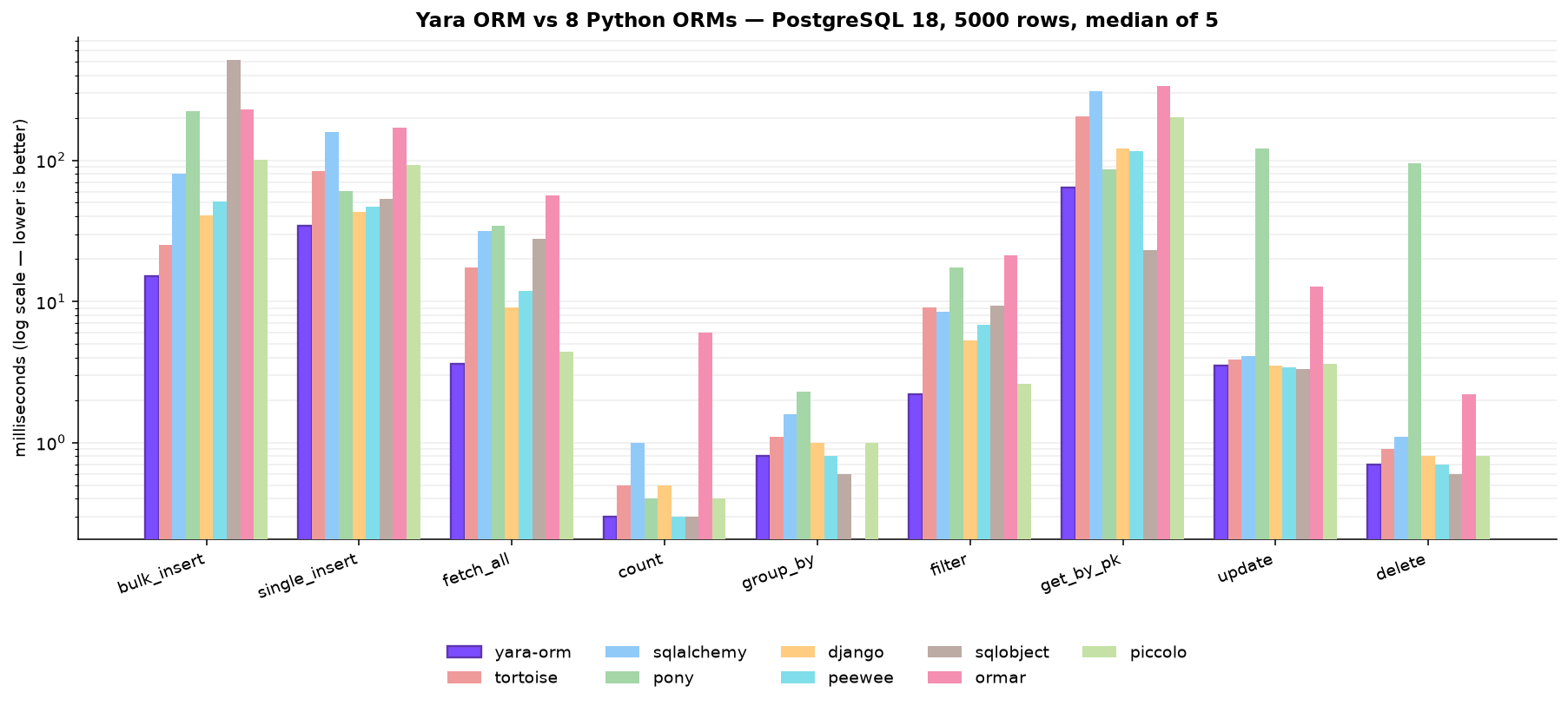
PostgreSQL 18, Apple Silicon, Python 3.12, N=5000, median of 5 (ms, lower is better).
| operation | yara-orm | tortoise | sqlalchemy | pony | django | peewee | sqlobject | ormar | piccolo |
|---|---|---|---|---|---|---|---|---|---|
| bulk_insert | 15.2 | 25.2 | 80.8 | 223.8 | 40.5 | 51.1 | 513.3 | 227.5 | 100.7 |
| single_insert | 34.4 | 84.1 | 158.7 | 60.8 | 42.9 | 46.6 | 53.3 | 169.1 | 92.3 |
| fetch_all | 3.6 | 17.3 | 31.6 | 34.4 | 9.1 | 11.9 | 27.8 | 56.6 | 4.4 |
| count | 0.3 | 0.5 | 1.0 | 0.4 | 0.5 | 0.3 | 0.3 | 6.0 | 0.4 |
| group_by | 0.8 | 1.1 | 1.6 | 2.3 | 1.0 | 0.8 | 0.6 | - | 1.0 |
| filter | 2.2 | 9.1 | 8.4 | 17.5 | 5.3 | 6.8 | 9.3 | 21.2 | 2.6 |
| get_by_pk | 64.1 | 205.9 | 310.4 | 86.0 | 121.1 | 115.6 | 23.1 | 336.9 | 201.6 |
| update | 3.5 | 3.9 | 4.1 | 121.1 | 3.5 | 3.4 | 3.3 | 12.8 | 3.6 |
| delete | 0.7 | 0.9 | 1.1 | 95.5 | 0.8 | 0.7 | 0.6 | 2.2 | 0.8 |
group_by is a GROUP BY … COUNT/SUM … HAVING aggregate query (Ormar has no
GROUP BY API, hence -).
Speedup vs Yara ORM (competitor time ÷ yara-orm time; >1 means Yara ORM is faster):
| operation | tortoise | sqlalchemy | pony | django | peewee | sqlobject | ormar | piccolo |
|---|---|---|---|---|---|---|---|---|
| bulk_insert | 1.7x | 5.3x | 14.7x | 2.7x | 3.4x | 33.8x | 15.0x | 6.6x |
| single_insert | 2.4x | 4.6x | 1.8x | 1.2x | 1.4x | 1.6x | 4.9x | 2.7x |
| fetch_all | 4.8x | 8.7x | 9.5x | 2.5x | 3.3x | 7.7x | 15.6x | 1.2x |
| count | 2.0x | 3.6x | 1.5x | 1.8x | 1.0x | 1.2x | 22.5x | 1.6x |
| group_by | 1.4x | 1.9x | 2.8x | 1.3x | 1.0x | 0.7x | - | 1.2x |
| filter | 4.1x | 3.8x | 7.9x | 2.4x | 3.1x | 4.2x | 9.6x | 1.2x |
| get_by_pk | 3.2x | 4.8x | 1.3x | 1.9x | 1.8x | 0.4x | 5.3x | 3.1x |
| update | 1.1x | 1.2x | 35.0x | 1.0x | 1.0x | 0.9x | 3.7x | 1.0x |
| delete | 1.2x | 1.5x | 129.6x | 1.1x | 0.9x | 0.9x | 2.9x | 1.1x |
Yara ORM is fastest or tied on every operation; the only place any ORM edges ahead is
SQLObject on get_by_pk (0.4× — 23.1 vs 64.1 ms), where its lean in-process sync
active-record avoids the async event-loop hop on single-row point reads — the same
latency-bound floor that keeps Pony close on get_by_pk. Everything throughput-shaped is
far ahead (bulk_insert up to 34×, fetch_all up to 16×, delete 130× vs Pony's
row-by-row loop).
MySQL¶
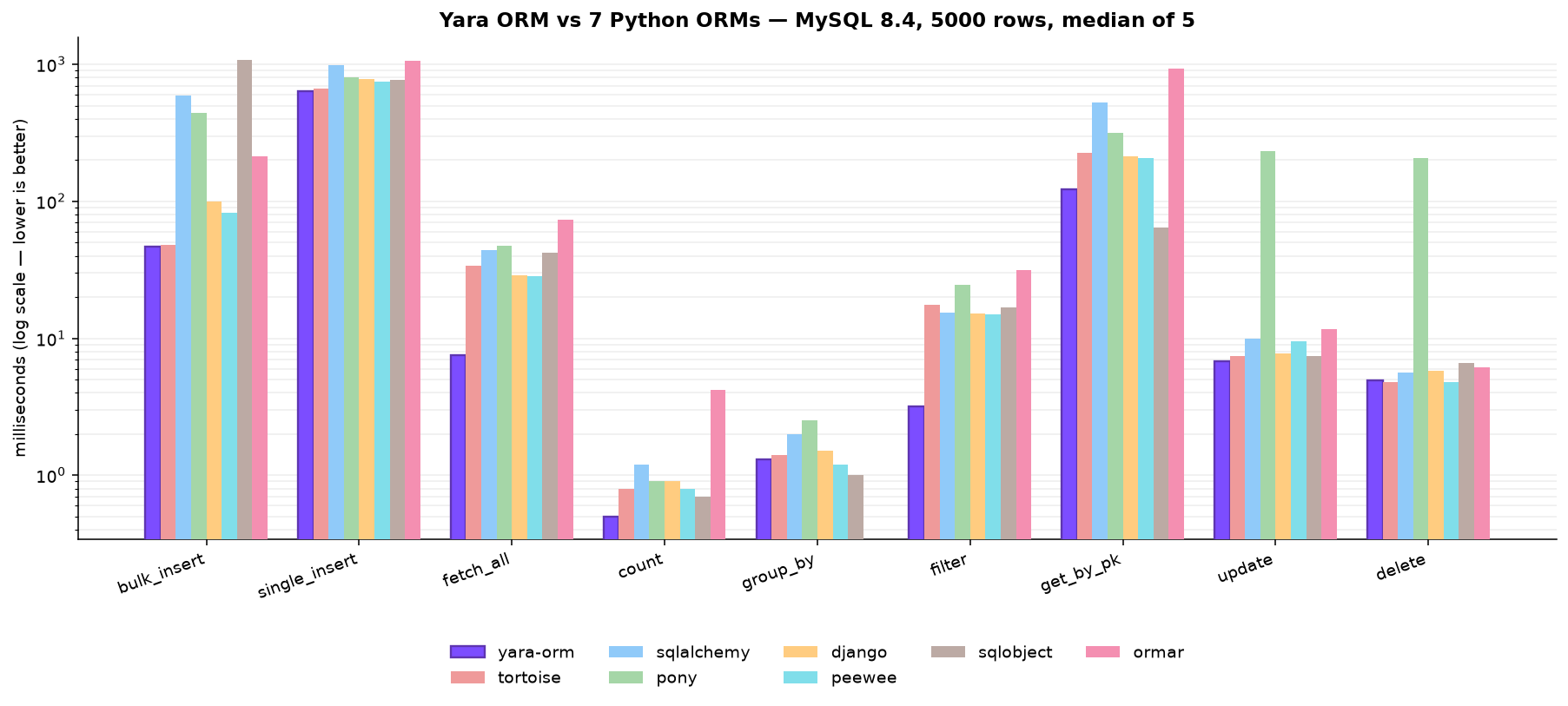
MySQL 8.4 (Docker), Apple Silicon, Python 3.12, N=5000, median of 5 (ms, lower is better). Tortoise runs over asyncmy, SQLAlchemy/Ormar over aiomysql, the sync ORMs over pymysql. Piccolo has no MySQL backend, so it is absent here:
| operation | yara-orm | tortoise | sqlalchemy | pony | django | peewee | sqlobject | ormar |
|---|---|---|---|---|---|---|---|---|
| bulk_insert | 46.8 | 48.2 | 596.1 | 443.5 | 100.0 | 82.1 | 1076.6 | 212.3 |
| single_insert | 638.7 | 660.6 | 985.1 | 800.6 | 783.4 | 743.5 | 773.8 | 1062.2 |
| fetch_all | 7.5 | 33.8 | 44.3 | 47.7 | 28.7 | 28.5 | 42.0 | 73.0 |
| count | 0.5 | 0.8 | 1.2 | 0.9 | 0.9 | 0.8 | 0.7 | 4.2 |
| group_by | 1.3 | 1.4 | 2.0 | 2.5 | 1.5 | 1.2 | 1.0 | - |
| filter | 3.2 | 17.5 | 15.5 | 24.6 | 15.1 | 14.9 | 16.8 | 31.3 |
| get_by_pk | 122.0 | 226.1 | 524.2 | 315.4 | 214.0 | 208.0 | 64.6 | 924.3 |
| update | 6.8 | 7.4 | 9.9 | 232.4 | 7.7 | 9.5 | 7.4 | 11.7 |
| delete | 4.9 | 4.8 | 5.6 | 207.0 | 5.8 | 4.8 | 6.6 | 6.1 |
Yara ORM is fastest or tied on every operation here too (fetch_all 3.8–9.7×,
filter 4.7–9.8×, get_by_pk 1.7–7.6×), except SQLObject's leaner get_by_pk (0.5×) and the sub-millisecond group_by where peewee/SQLObject edge it (0.8–0.9×).
The two latency-bound operations include the Docker-network round trip, and
single_insert (~0.6–1.1 s across the board) is dominated by InnoDB's per-commit
fsync — a durability cost every ORM pays equally.
MariaDB¶
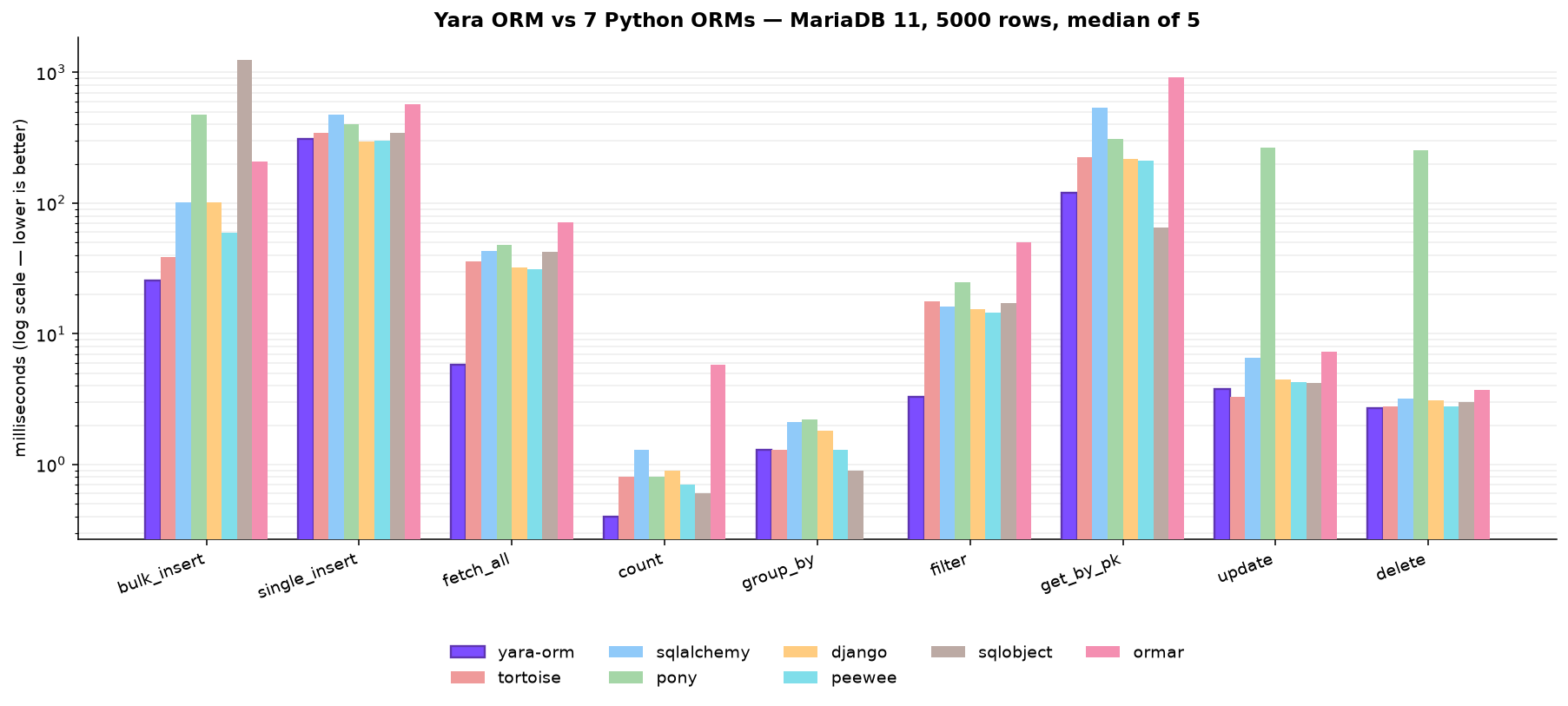
MariaDB 11 (Docker), Apple Silicon, Python 3.12, N=5000, median of 5 (ms, lower
is better). Every competitor connects through its MySQL driver; yara-orm
auto-detects MariaDB and switches to its RETURNING dialect. Piccolo has no MySQL
backend, so it is absent here:
| operation | yara-orm | tortoise | sqlalchemy | pony | django | peewee | sqlobject | ormar |
|---|---|---|---|---|---|---|---|---|
| bulk_insert | 25.6 | 38.4 | 101.2 | 473.5 | 100.8 | 59.6 | 1247.3 | 208.4 |
| single_insert | 311.9 | 345.2 | 476.6 | 403.7 | 296.3 | 299.0 | 345.6 | 573.5 |
| fetch_all | 5.8 | 36.1 | 43.2 | 48.1 | 32.1 | 31.0 | 42.7 | 71.6 |
| count | 0.4 | 0.8 | 1.3 | 0.8 | 0.9 | 0.7 | 0.6 | 5.8 |
| group_by | 1.3 | 1.3 | 2.1 | 2.2 | 1.8 | 1.3 | 0.9 | - |
| filter | 3.3 | 17.7 | 16.2 | 24.8 | 15.4 | 14.6 | 17.3 | 50.0 |
| get_by_pk | 120.8 | 224.8 | 541.4 | 310.9 | 217.8 | 210.7 | 64.8 | 914.8 |
| update | 3.8 | 3.3 | 6.6 | 264.7 | 4.5 | 4.3 | 4.2 | 7.3 |
| delete | 2.7 | 2.8 | 3.2 | 252.1 | 3.1 | 2.8 | 3.0 | 3.7 |
Yara ORM leads or ties every operation except SQLObject's leaner get_by_pk
(0.5×) and the sub-millisecond group_by (SQLObject 0.7×). It wins the throughput
ops decisively (fetch_all 5.4–12.4×, filter 4.4–15.2×, bulk_insert up to
49× vs SQLObject). single_insert, update and delete are near ties across every
ORM because they are database-bound, not client-bound: single inserts are
paced by MariaDB's per-commit disk fsync (high run-to-run variance), and
update/delete are one server-side set statement each — the client just sends
SQL and reads a rowcount, so there is no marshaling for the Rust hot path to
accelerate. MariaDB's single_insert (~310 ms) is notably faster than MySQL 8's
here — a lighter default commit path.
SQLite¶
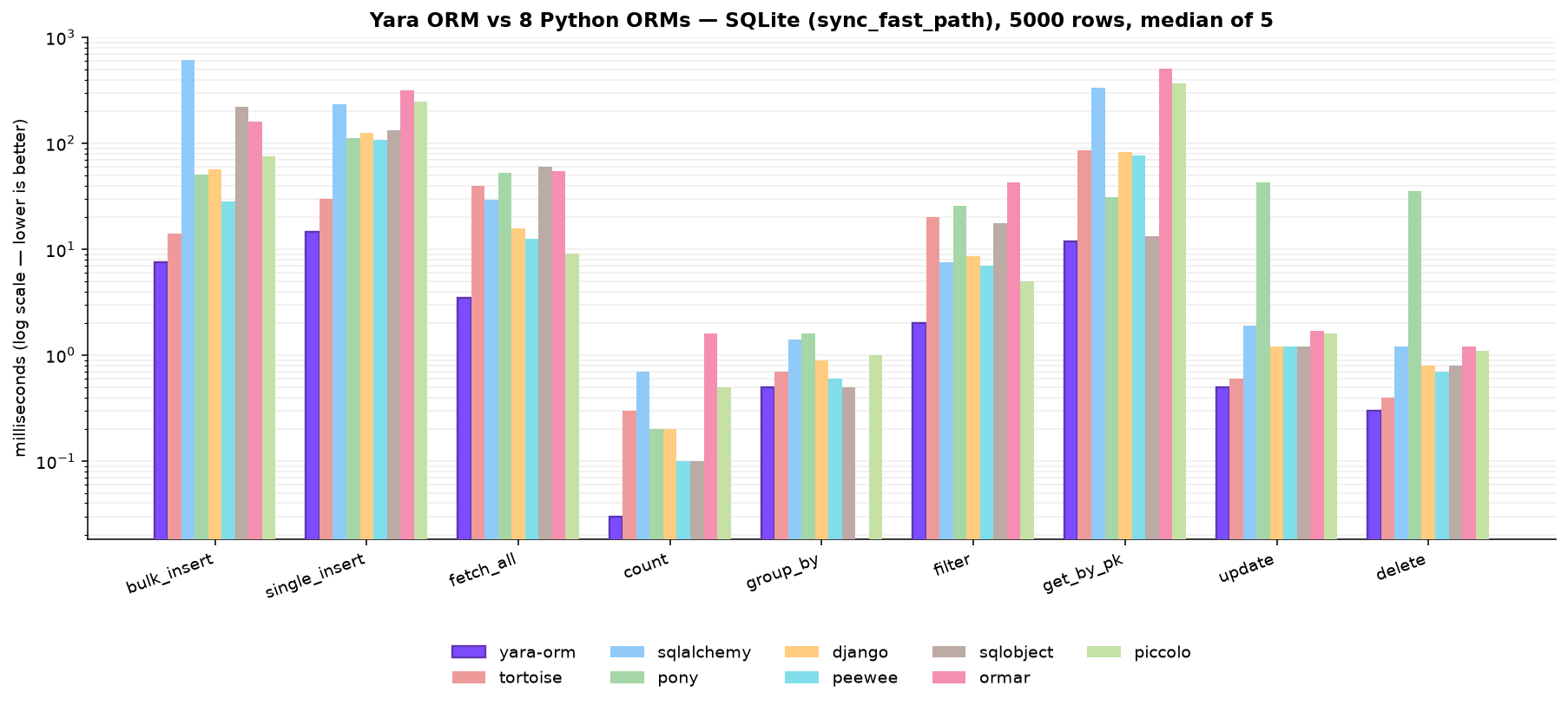
Python 3.12, N=5000, median of 5 (ms, lower is better). SQLite is in-process, so
these use its recommended sync_fast_path=1
config — statements run synchronously on the calling thread, since an embedded
database has no I/O to overlap and the async bridge would be pure overhead.
| operation | yara-orm | tortoise | sqlalchemy | pony | django | peewee | sqlobject | ormar | piccolo |
|---|---|---|---|---|---|---|---|---|---|
| bulk_insert | 7.5 | 14.1 | 612.6 | 50.8 | 57.3 | 28.2 | 221.3 | 160.7 | 75.7 |
| single_insert | 14.6 | 30.1 | 234.4 | 111.7 | 124.8 | 106.9 | 132.1 | 315.5 | 247.3 |
| fetch_all | 3.5 | 39.7 | 29.4 | 52.2 | 15.8 | 12.6 | 60.5 | 54.9 | 9.1 |
| count | 0.0 | 0.3 | 0.7 | 0.2 | 0.2 | 0.1 | 0.1 | 1.6 | 0.5 |
| group_by | 0.5 | 0.7 | 1.4 | 1.6 | 0.9 | 0.6 | 0.5 | - | 1.0 |
| filter | 2.0 | 20.1 | 7.6 | 25.7 | 8.6 | 7.0 | 17.7 | 42.7 | 5.0 |
| get_by_pk | 11.9 | 86.0 | 332.9 | 31.0 | 82.9 | 76.4 | 13.3 | 510.4 | 368.3 |
| update | 0.5 | 0.6 | 1.9 | 42.8 | 1.2 | 1.2 | 1.2 | 1.7 | 1.6 |
| delete | 0.3 | 0.4 | 1.2 | 35.3 | 0.8 | 0.7 | 0.8 | 1.2 | 1.1 |
Yara ORM is fastest or tied on every operation (SQLObject's hand-written raw-SQL
aggregate, bypassing its ORM entirely, ties the sub-millisecond group_by).
It now wins the point reads it trailed on with the default async bridge — get_by_pk
1.1× vs SQLObject and 2.6× vs Pony — because the fast path removes the per-statement
asyncio hop that a synchronous in-process driver never pays. Throughput stays far ahead
(bulk_insert 1.9–82×, fetch_all 2.6–17×, filter 2.5–21×, single_insert 2.1× vs
Tortoise). On the default async path (no fast path), the per-statement bridge costs tens
of microseconds on sequential point reads, so SQLObject's lean sync active-record leads
get_by_pk there instead — the delta is quantified in
the sync fast path section below.
Opt-in SQLite sync fast path¶
On SQLite, per-statement work is microseconds, so the asyncio bridge dominates:
scheduling the statement on the tokio runtime and waking the event loop costs
~40µs around ~0.5–6µs of actual SQLite work. Adding sync_fast_path=1 to
the URL removes that bridge — statements run synchronously on the calling
thread (GIL released) and return already-completed awaitables, cutting a warm
point query from ~40µs to ~6µs (~7×):
benchmarks/bench_features.py (Apple Silicon, Python 3.13, median of 5),
default vs fast path:
| operation | default (ms) | sync_fast_path=1 (ms) | speedup |
|---|---|---|---|
| insert_autocommit | 17.26 | 6.40 | 2.7× |
| insert_one_tx | 11.17 | 1.58 | 7.1× |
| insert_savepoint_each | 31.79 | 2.22 | 14.3× |
| forward_n_plus_1 | 23.76 | 5.29 | 4.5× |
| forward_select_related | 0.73 | 0.69 | 1.1× |
| reverse_n_plus_1 | 5.98 | 2.37 | 2.5× |
| reverse_prefetch | 0.48 | 0.41 | 1.2× |
| fetch_full | 0.23 | 0.19 | 1.2× |
| values | 0.21 | 0.16 | 1.3× |
| values_list | 0.13 | 0.09 | 1.4× |
The per-statement operations (point inserts, N+1 fan-outs, savepoints) win big; single-query bulk fetches only shed one bridge crossing each.
Read the caveats before opting in
The event loop is blocked for the duration of each statement, and awaiting a completed awaitable may not yield to the loop (task fairness changes). Opt in for microsecond-statement workloads — tests, scripts, benchmarks, low-contention apps — and read the full caveat list first. The flag is SQLite-only.
uvloop on the default async path¶
Independently of the fast path: on the default async path, running your app under uvloop cuts roughly 20% of the per-query overhead with zero code changes (the bridge's event-loop wakeups get cheaper), and it composes with every backend, PostgreSQL included:
Why it's fast¶
- Rust hot path — parameter binding and row decoding happen in compiled code; the async bridge (PyO3 + tokio) keeps the event loop free.
- Positional row decoding — for SELECTs the engine returns column values with no per-row column-name allocation and no dict; Python fills instances by index using a precomputed decode plan.
- Compiled-SQL caching — the SELECT column list, single-row INSERT and a fast-path
simple
get()are built once per model and reused, andprepare_cachedskips re-parse. - Connection pooling — deadpool keeps warm connections, so steady-state latency excludes connect cost.
Faster reads with projections
For pure projections, values_list() / values() select only the
requested columns and skip model construction (~1.7–2.2× faster than a full fetch).
Run it yourself¶
make bench # PostgreSQL cross-ORM benchmark (9 ORMs)
make bench-mysql # same comparison on MySQL
make bench-sqlite # same comparison on SQLite
See benchmarks/README.md
for setup and tuning knobs (BENCH_N, BENCH_REPEAT, …).